uc电脑园 – 你的电脑系统管家

具有百万参数的训练网络近期获得了巨大进展。微软近日更新了 DeBERTa (Decoding-enhanced BERT with disentangled attention)模型,训练了一个由 48 个 Transformer 层组成,拥有 15 亿个参数的模型。
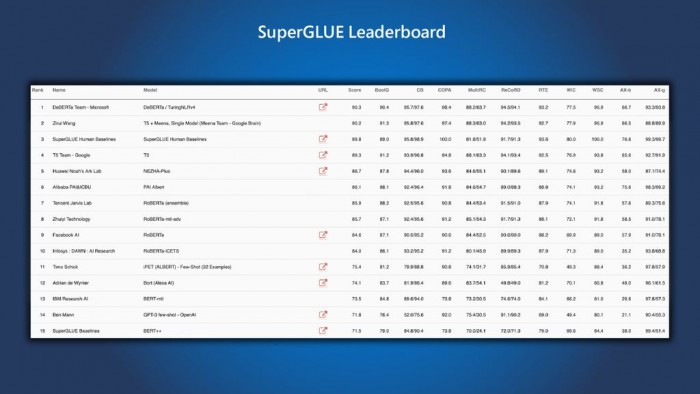
性能的大幅提升使得单个 DeBERTa 模型在 SuperGLUE 语言处理和理解上的宏观平均得分首次超过了人类的表现(89.9 分 VS 89.8分),以相当大的优势(90.3分对89.8分)超过了人类基线。
SuperGLUE 基准包括广泛的自然语言理解任务,包括问题回答、自然语言推理。该模型也以 90.8 的宏观平均分位居 GLUE 基准排名的前列。

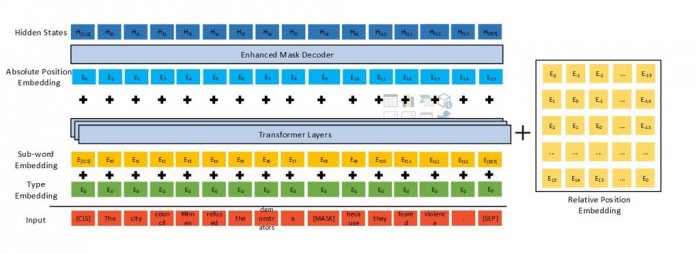
DeBERTa 使用三种新颖的技术改进了之前最先进的PLM(例如BERT、RoBERTa、UniLM):一个分离的注意力机制、一个增强的掩码解码器和一个用于微调的虚拟对抗训练方法。
相比较由 110 亿个参数组成的谷歌 T5 模型,拥有 15 亿个参数的 DeBERTa 在训练和维护上更加节能,而且更容易压缩和部署到各种环境的应用中。
DeBERTa在SuperGLUE上超越人类的表现,标志着向通用AI迈进的重要里程碑。尽管在SuperGLUE上取得了可喜的成绩,但该模型绝不是达到NLU的人类级智能。
微软将把这项技术整合到微软图灵自然语言表示模型的下一个版本中,用于Bing、Office、Dynamics和Azure认知服务等地方,通过自然语言为涉及人机、人与人交互的各种场景提供动力(如聊天机器人、推荐、答题、搜索、个人助理、客服自动化、内容生成等)。此外,微软还将向公众发布15亿参数的DeBERTa模型和源代码。
uc电脑园提供的技术方案或与您产品的实际情况有所差异,您需在完整阅读方案并知晓其提示风险的情况下谨慎操作,避免造成任何损失。

浏览次数 28806
浏览次数 10642
浏览次数 9031
浏览次数 8117
浏览次数 5231


未知的网友